I'm building this actually (been at it for a couple years :-/). But you know what, deviantArt got a lot better at browsing pictures a few months ago, with their 'more like this' feature. You should check it out.
In the same vein, I've been using Zwibbler ( http://zwibbler.com/demo/ ) for all the illustrations on my blog ( http://vjeux.com ) and it's been really nice to have images that look like they have been hand drawn.
I just took the ones I liked and then deleted out the words that were specific to that image and left the ones that were providing the style of the image. So for example on the first one I would delete "an cute kitsune in florest" but would keep "colorfully fantast concept art". Then I just added a comma separated list of the of the features I wanted in my picture. It took a lot more trial and error than I thought and adding sentences seemed to be worse than just individual words. I am sure I barely scratched the surface of interfacing with the tool correctly but the space is moving so fast its not the kind of thing I want to spend my time learning right now just to have that knowledge deprecate in 6 months.
I ran that image through the library with the default settings and it came out with an image that is in my opinion much better than all of the approaches shown there
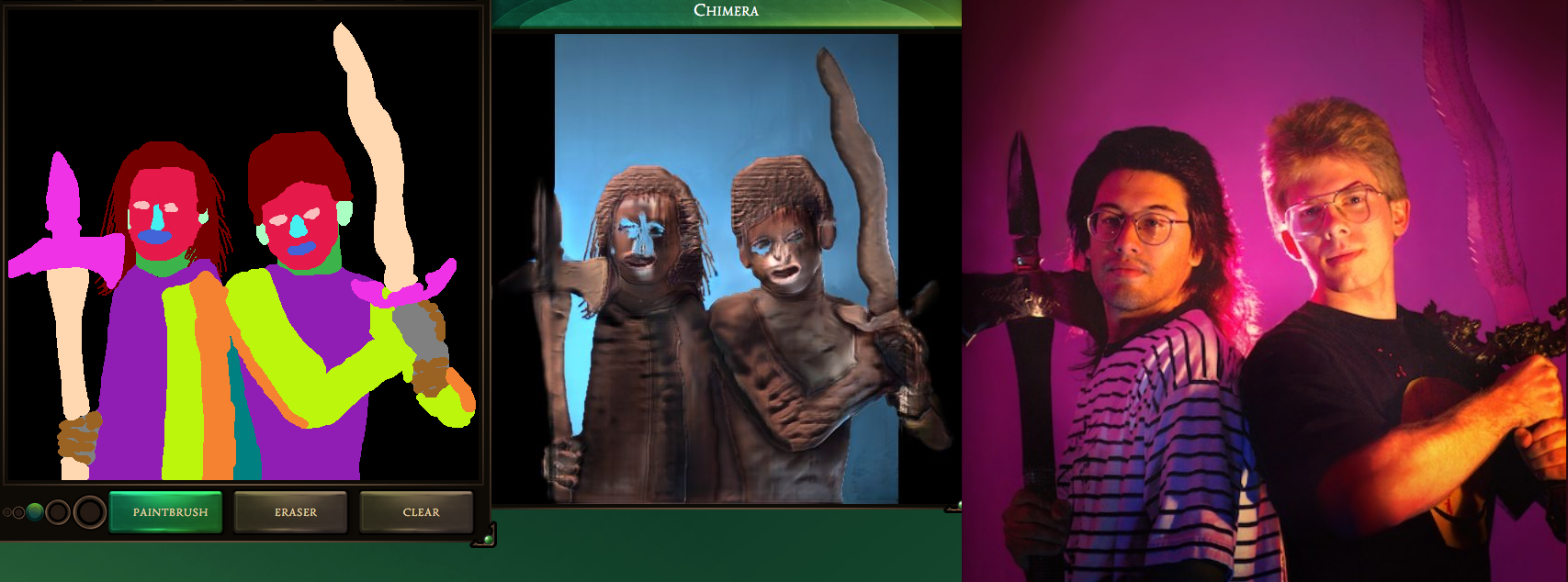
Otherwise my clumsy, misshapen caricature turned out surprisingly nice. (I mean, relative to how nonsensical its anatomy is.) The shapes are followed very precisely, so yes, blobby input begets blobby output.
so someone can just write a script to generate the full image right? since instructions are the same for each pixel. Would make it easier to check your work..
The problem with this is that it's prone to error (doesn't have error correcting bits). Unfortunately, that combined with speed of scanning is really what's key for codes.
I have worked in the space, making some strides in speed & error correction.
Your best bet is actually an overlay of two codes. A regular image (for humans), plus a code embedded in a color space (see linked post for how to do that).
You could have asked those tools to create images like the ones found in AI catalogs like https://lexica.art/ and https://www.krea.ai/ and then compared with what you can get for $10. This would be a comparison more favorable to AI
{kind=link}
Author has a nice repo with other doodles:
https://github.com/girliemac/a-picture-is-worth-a-1000-words
I really wish there were some way to find and navigate good OERs like these.
reply