Nvidia's NVIDIA DGX™ GH200 supercomputer links 256 Grace Hopper CPU+GPU chips with 576 GBs of unified memory each into a single 144 terabyte GPU address space.
nabla9 said "one Grace Hopper" not "one GH200 pod".
Actually, DGX GH200 seem to come in different sizes, something that I can't find clearly stated on Nvidia's website, but what I do see are entirely inconsistent specs. I'm thinking they've changed it a few times.
> Nvidia uses a new NVLink Switch System with 36 NVLink switches to tie together 256 GH200 Grace Hopper chips and 144 TB of shared memory into one cohesive unit that looks and acts like one massive GPU
This device has a fully switched fabric allowing comms between any of the 256 "superchip" clusters at 900GB/s. That is dramatically faster than a direct host to GPU 32-lane PCI-E connection (which is crazy), and obviously dwarfs any existing machine to machine connectivity. The actual usability of shared memory across the array is improved significantly.
I mean...nvidia has obviously been using DMA for decades. This isn't just DMA.
I’m not sure of all the details of the architecture, but my understanding is that there’s all sorts of “GPU Direct Storage” and massive on-chip CPU/GPU shared memory spaces on the new GH100s, plus all the Mellanox stuff for interconnects. At least in the datacenter space, anyway.
It should be mapped as one address space, so yes to the loading across multiple GPU question. It's not fully unified though, at this scale of computer it's simply impossible to put 100s of GB on an SOC like that. Instead, the GPU and CPU have DMA over PCI and NvLink, which is plenty fast for AI and scientific compute purposes. "Unified memory" doesn't make much sense for supercomputers this large.
It's 24 Nvidia DGX-1 servers, which contain 8 GPUs each. It's worth noting that Nvidia already have their own 124-node DGX-1 installation, which would have 992 GPUs.
This will give us servers for deep learning that can have 8 GPUs and a couple of NVMe disks on PCI 4.0 (32 GB/s). With very good inter-GPU I/O and access to NVMe, it will enable commodity servers that are competitive with Nvidia's DGX-1 or DGX2, that include SXM2 (Nvlink with 80GB/s between GPUs).
I've not dug into this enough yet but all prior generations of Nvidia GPUs have had caveats when adding steps to unify main memory. It certainly isn't "one address space" as far as the OS is concerned, perhaps Nvidia is saying this is sufficiently well enough abstracted in CUDA 8.
The true land of milk and honey is prophesied in Volta when paired with Power 9 and CAPI, first appearing in the Summit and Sierra systems.
This is kind of what nvswitch does, albeit in a proprietary architecture. All 16 GPUs in an NVSwitch can see the memory space of all others, and any reads/writes are transparently performed on the correct GPU. This effectively gives a 512GB address space of HBM2 memory.
In contrast, a typical DDR4 RAM on your typical desktop is 0.05 TBps, so yeah, 7.2TBps external bandwidth between GPUs is quite a lot.
-----------
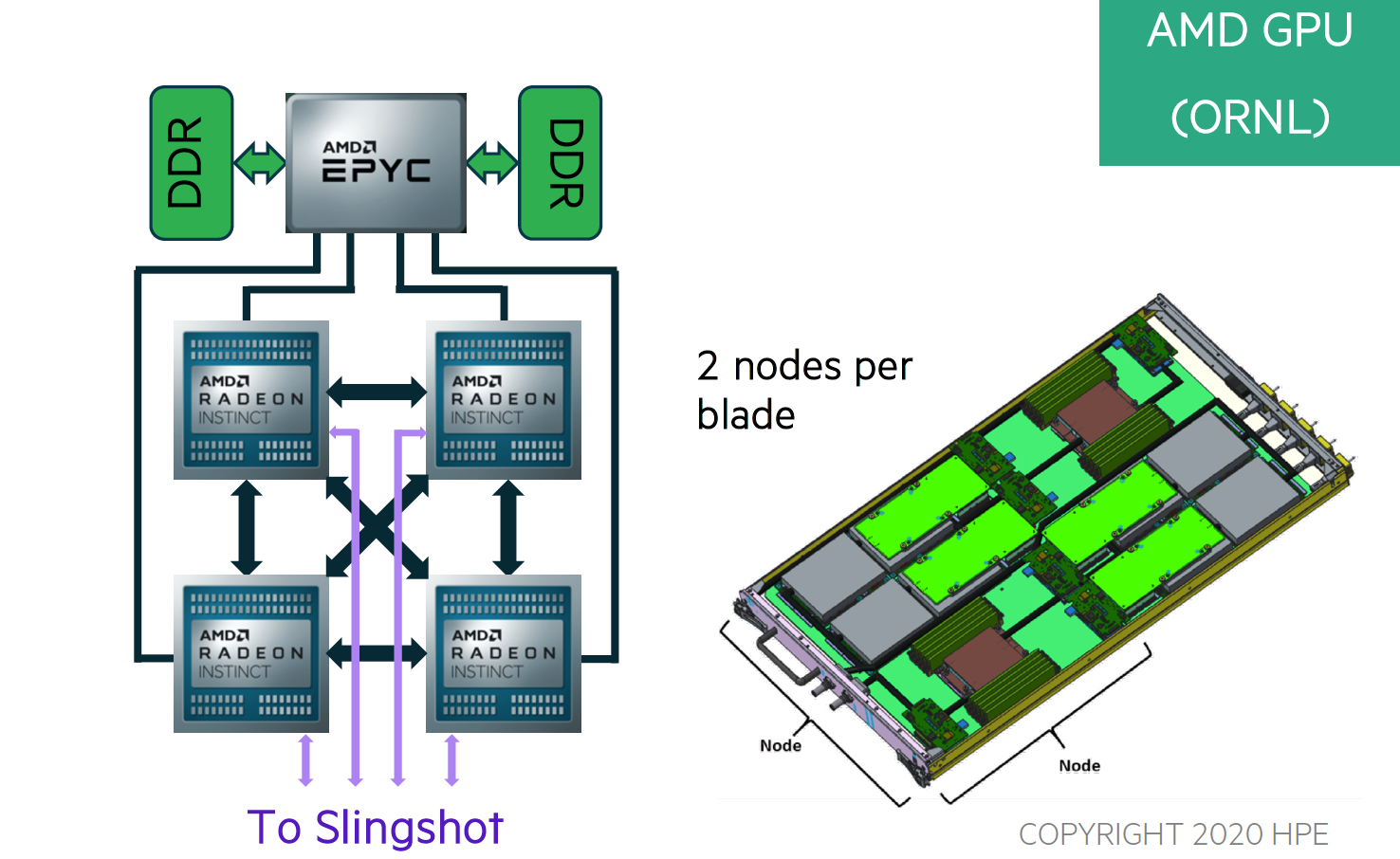
For Frontier, the Slingshot NICs are 100GBps each. So each node can communicate with more bandwidth to each other than your typical Desktop computer has RAM-bandwidth.
>And they are able to be linked together such that they all share the same memory via NVLink. This makes them scalable for processing the large data and holding the models for the larger scale LLMs and other NN/ML based models.
GPUs connected with NVLink do not exactly share memory. They don't look like a single logical GPU. One GPU can issue loads or stores to a different GPU's memory using "GPUDirect Peer-To-Peer", but you cannot have a single buffer or a single kernel that spans multiple GPUs. This is easier to use and more powerful than the previous system of explicit copies from device to device, perhaps, but a far cry from the way multiple CPU sockets "just work". Even if you could treat the system as one big GPU you wouldn't want to. The performance takes a serious hit if you constantly access off-device memory.
NVLink doesn't open up any functionality that isn't available over PCIe, as far as I know. It's "merely" a performance improvement. The peer-to-peer technology still works without NVLink.
NVidia's docs are, as always, confusing at best. There are several similarly-named technologies. The main documentation page just says "email us for more info". The best online documentation I've found is in some random slides.
"Here’s the funny bit. The UALink 1.0 specification will be done in the third quarter of this year, and that is also when the Ultra Accelerator Consortium will be incorporated to hold the intellectual property and drive the UALink standards. That UALink 1.0 specification will provide a means to connect up to 1,024 accelerators into a shared memory pod. In Q4 of this year, a UALink 1.1 update will come out that pushes up scale and performance even further. It is not clear what transports will be supported by the 1.0 and 1.1 UALink specs, or which ones will support PCI-Express or Ethernet transports.
NVSwitch 3 fabrics using NVLink 4 ports could in theory span up to 256 GPUs in a shared memory pod, but only eight GPUs were supported in commercial products from Nvidia. With NVSwitch 4 and NVLink 5 ports, Nvidia can in theory support a pod spanning up to 576 GPUs but in practice commercial support is only being offered on machines with up to 72 GPUs in the DGX B200 NVL72 system."
The TITAN RTX NVLink™ bridge connects two TITAN RTX cards together over a 100 GB/s interface. The result is an effective doubling of memory capacity to 48 GB, so that you can train neural networks faster, process even larger datasets, and work with some of the biggest rendering models."
Lower-end GPUs like Intel's integrated graphics and console hardware are doing this, but high-end desktop GPUs do not- they still have separate memory spaces (though they may share some memory).
{kind=link}
https://www.nvidia.com/en-us/data-center/dgx-gh200/
reply