Per (0) I don't think "don't decode until you scroll" is done yet. This issue alone makes Firefox annoying for use on image boards and "infiniscroll"-style galleries like Facebook's.
Also, "discard images when you scroll them offscreen" was disabled in (1) because it broke sites with lots of images (like Pinterest and Tumblr Archives, according to the bug).
These two issues alone make Firefox pretty painful for a lot of common use cases on real-world machines (like my old web browsing machine with only 2GB of RAM).
I have already found one case in Firefox where this is true. FF will load the image data in background tabs, but it won't decode it (e.g. render a JPG) until you switch to that tab. I may be nitpicking but the extra half-second or so bothers me like texture pop-in in a game. So I go to about:config and set image.mem.decodeondraw and image.mem.discardable to false.
Images that aren't visible aren't decoded as they are downloaded, or something like that. It reduces peak memory usage on image-heavy pages. It should be coming in Firefox 26.
Firefox downloads image data but doesn't decode it until you browse to that spot on the page. Do you think that's what you're seeing? You can disable that in about:config, just toggle image.mem.decodeondraw to false.
Doesn't a JavaScript implementation offset most of the performance benefits? Today we have browsers that are smart about when to cache the decoded image and when not, etc; does that have to be reimplemented in javascript?
If image decoding is asynchronous (don't know - guessing it is already?) and you decode them when they get near to the viewport and not just when they become visible, then it should always be decoded by the time you scroll to it and yet never jank the page. Scrolling a long way really fast probably means there's a small delay while it decodes images, but surely that's worth it to save gigabytes of memory?
Chrome does this for a long time now and I don't consider it an issue. You see a frozen version of the last decoded keyframe until the next one is decoded. Elegant solution IMO.
I'm pretty sure it only discards the original after x number of other (new) images have been decoded. (Or perhaps it's memory footprint based?)
I ran into a Chrome performance bug years ago with animations, because the animation had more frames than the decoded cache size. Everything ground to a halt on the machine when it happened. Meanwhile older unoptimized browsers ran it just fine.
>> Does the javascript decoder download the images, or does the browser do that, then the javascript simply decode it?
Right now, it would appear that the with a hard reload of the demo: http://bellard.org/bpg/lena.html on chromium, the BPG images are initially loaded with the page, then the posts.js file scans through the page's images to find the ones who's src ends in '.bpg', then posts.js re-downloads the same files with ajax, which are then decoded to PNG files rendered in canvas tags with no identifying information.
The extra request to re-download images is unnecessary but easily removed to just process the data loaded with the initial page load.
>> Can CSS reference them without javascript changing the styles?
Not from what I can see. The images are being rendered to canvas elements without any identifying information. The decoder will need to be modified to add identifying id's or classes. This again is an easy fix.
>> Can they be cached locally if downloaded directly?
This is what I perceive to be an issue. Try downloading the image rendered to the 5kb bpg example... The image that is being rendered is a 427.5kb PNG and that's for a 512x512 image size.
PNGs aren't lossy... so any difference in file size is going to be the product of rendering size or how much the bpg compression has simplified the source image. ( I'm guessing the file size follows something like a logarithmic curve where it jumps initially based on rendered image dimensions and then approaches a limit as the compression approaches lossless. )
Because of the rendered out PNGs' large file size, I would expect that if you are rendering out large images or a lot of images, you would definitely use more resources than with comparable quality JPGs regardless of whether you cache the BPGs for rendering and you would indeed experience the drawbacks you mentioned in both memory and page-load time.
That being said, this is a cool idea, an incredible proof of concept and I'm very thankful to Fabrice for putting it out there.
Does the javascript decoder download the images, or does the browser do that, then the javascript simply decode it? If it downloads them itself, then any parallel fetching by browsers will stop working. And if they are decoded by javascript, they will take (very slightly) longer, and both the encoded and decoded images need to be held in memory both in javascript, and the browser. Are they decoded to .bmp, .jpg, .png? Can CSS reference them without javascript changing the styles? Can they be cached locally if downloaded directly?
If you needed this for any page that loaded lots of images, all of the above would significantly increase page-load time, and memory usage. Especially on a mobile browser, it would use more resources (hence more battery), than otherwise. So personally I wouldn't like to see this be the future. Maybe just as a fall back, but detection for that might be a little hard.
Not necessarily, the decoding can be stopped once you get enough usable information in regards to the usage of the image (display size ...) with the same source image. That's neat!
Thanks for the info. I wasn't aware firefox would block the images. I don't have any specific tracking on the images, but I'll look into why that might be a problem.
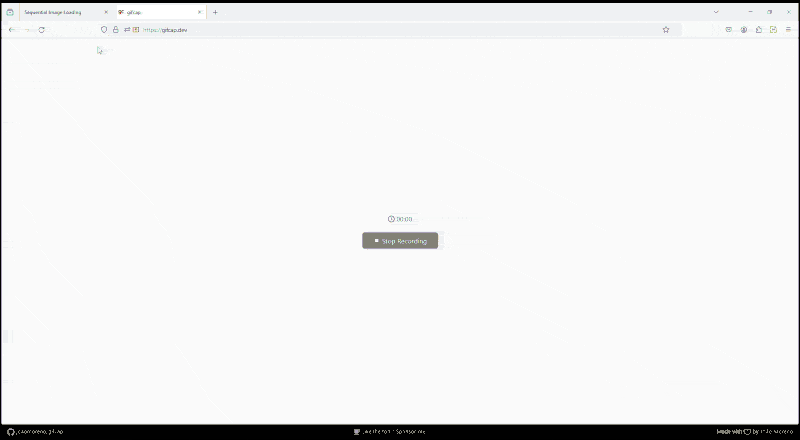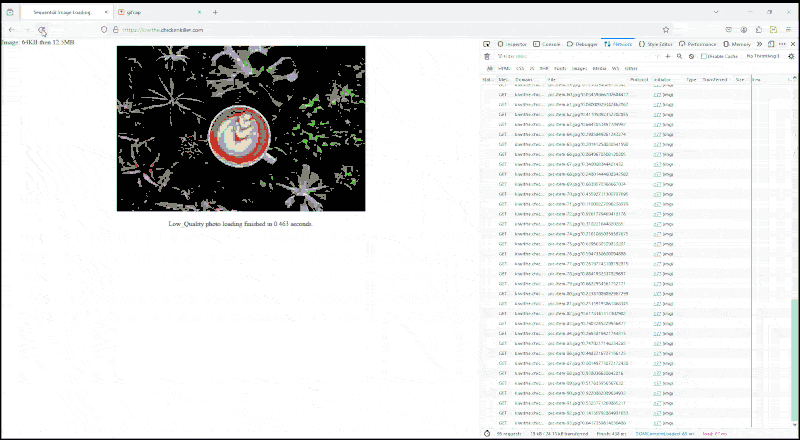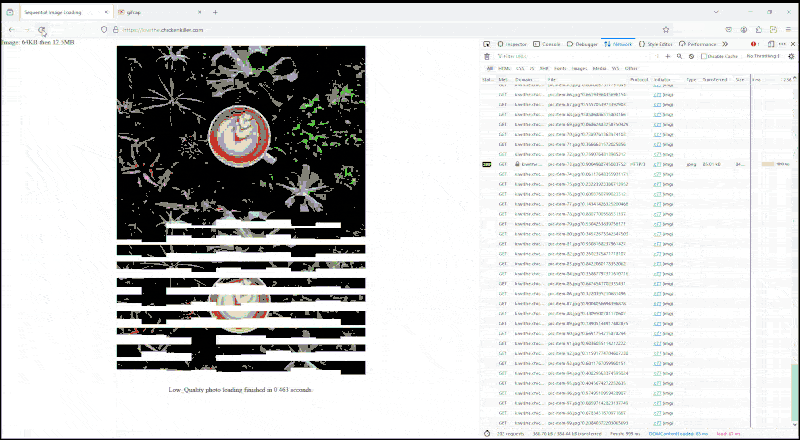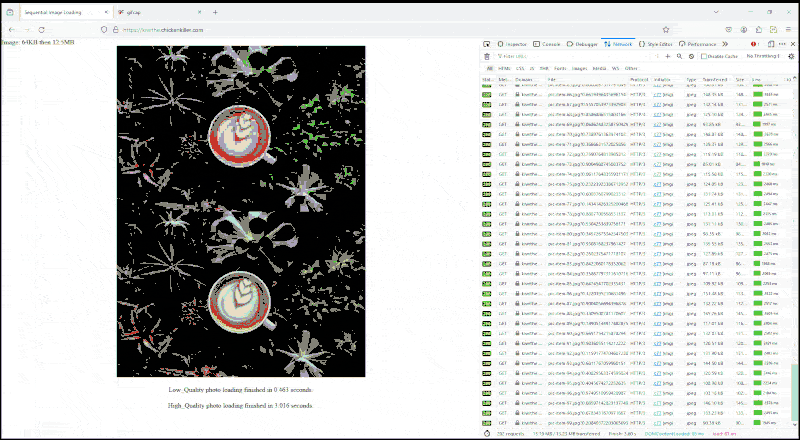
Haven't seen images load like that since the dial-up modem days.
I cludged together a node.js application in 2013 to load JPEG SOS segments separately to the browser. The idea was to tie it to depth in a VR application, like level-of-detail maps in game engines, but 'online'. Turned out no browser like that much so I dropped the project.
{kind=link}
reply