Interesting article, but it all rests on the assumption that AI can produce quality software consistently. It only does a very weak job of proving this claim.
The amount of tech debt at my last job was soul crushing. Trying to keep your head above water as the bugs keep coming in and features keep getting requested. Trying to balance the needs of 10 different departments all asking for priority. And this is with a team of 50 software engineers. We’re already using AI, but still probably need an order of magnitude improvement to make a real impact. I’m sure it’s coming.
I’m hopeful AI can help all of us really tackle legacy software - rebuild it to be simpler, more secure, well tested and easier to maintain and iterate.
I kind of view companies and governments as super intelligences unto themselves. Capable of doing things individuals are not. That is what AI will be competing with and/or augmenting.
As an external consultant every time I see this scenario it’s always a group that is too busy digging with shovels to learn how to operate the backhoe.
Literally just last week I was showing several dev teams how to cut days out of their troubleshooting time by using an APM that can capture debug snapshots from production. Combine with source indexing during builds and code versioned with the Git commit id and you can jump to the line of code with the issue in about a minute. You’ll see the stack variables and everything. This is possible even in a distributed microservices monstrosity.
It takes like a day to wire this up.
“We’re too busy for that today, there’s an issue in production!”
The millions of lines of tech debt combined with the pace our company moves and volumes (high tech manufacturing) would blow your mind. It’s thunder dome.
Yeah. I think many or most large established codebases/software stacks could be an order of magnitude or two simpler (making them an order of magnitude or two easier to iterate on, in terms of both time and number of devs needed)
But the reality we've discovered is that there's a constant gravitational force pulling most dev orgs to keep increasing complexity, forever, much faster than the actual product increases in complexity. We can avoid this at the individual level, maybe the team level, but at this point it feels unavoidable at the company or industry level
I had a massive, tanklike ETL I had designed. Over-engineered, really. It was built to keep truckin' as best it could and issue instructions on what was wrong, exactly where, how to fix it, and so on. Missing data? Call one of these three people. Also, here's the file where you update if these people have left. Warnings over errors, errors over terminating. Pored over it, working out edge cases, then corner cases, then situations I was told would "never" happen. Then it was set free like a strandbeest to do its thing, only receiving reports, occasional requests for more data. Finally, something odd came up in warnings, but not in errors, and I was shocked. How did the system handle this? Got a little curious ... I guess I had a good day here and a good day there, because although I currently did not "get it," the program did. My contributions had built something which was not merely consistent, but collectively had become smarter than I for this problem. I think my little process was its own super intelligence in its hyper-specific niche.
99% of the code that you can generate via ChatGPT can be already be found in the form of an open source library, already packaged and ready to use. The number of libraries to solve various problems continues to grow each day.
Many of the questions you can ask to ChatGPT, if not already present in a project documentation, have been already asked on Stack Overflow, mailing lists, etc. and indexed by search engines. Typing a well formulated question in a search engine may likely take you to a valid answer these days.
When taking that into consideration, that leaves us with a very different narrative. LLMs can make a difference, but software engineers have been already reusing solutions to save effort for many decades now.
There are already programming languages that are close to natural language such as SQL and BASIC. Did the release of those mean the end of software engineering as an occupation? no. Each time programming gets easier, the result is often more programmers.
Finally, there are many expert developers on freelancing sites such as Upwork that you can hire, are "generally intelligent" beyond ChatGPT, and perhaps will cost you less than paying for OpenAI tokens. Still, organizations choose to hire full-time software engineers.
People don’t choose to go to a doctor. They are not given a choice of using the expert system - even if they can’t afford a doctor.
Chatbots for customer support never worked right, so it wasn’t a choice either. With gpt-powered bots, many - if not most will choose that over calling a helpline.
Definitely worth a read for the humor value of the nonsensical code that can't work and the uncritical acceptance of it by the author as a "clever hack". All made possible by the human hallucinating what "ASCII emoji" might mean in a parallel universe, but doesn't. A golden age of taking money away from idiot VCs is approaching.
In past iterations, what ease corresponded to was standardization: we went from multiple assembly languages to a C or BASIC, from addressing specific hardware to cross-platform APIs, and from defining multiple character encodings to standardization on Unicode.
Generative AI throws the switch in reverse, because it's indifferent to standardization: people are formulating questions about data and how to process it in their native tongues, skipping the encoding process and the need to study documentation altogether. There isn't a point where it becomes, "oh, but then you hit a brick wall and have to learn the real stuff to solve your problem". GPT helps relatively less as you go deeper and further away from a SO-type answer, but it's a gradual decay.
I disagree on the effect, ChatGPT / CoPilot is making it cheaper to produce more lines of code as a solution instead of requiring better understood and tested abstractions.
I believe this will cause an increase on the trend of technical debt.
There are several talks/papers/blogs on lines of code being a cost/liability and not a product/asset. (this blog post seems to assume the inverse)
Yeah, I was about to say the same thing. The use of technical debt is a bit “funny” in that they’re using it to refer to a deficit of software, whereas it’s more commonly used to refer to less-than-ideal code that will need to be fixed later.
For that reason, I could see AI-generated code leading to more tech debt since its output is, as the authors put it, “cheap enough to waste”. People might get the idea to just have it crank out AI code snippets with no real bearing on what they actually do or no real care to refactor said snippets for reuse / readability until their house of cards collapses.
It’s worth remembering that 95% of new companies fail fairly quickly. Assume that most code written by them never lives on after.
Writing code, like offering a product/service in the economy, is game theory. After a period of LOC / copypasta increase, there will be more need for development refactors.
Personally, I’m trying to use LLMs to learn to upgrade my knowledge of abstractions and getting experience with refactoring using CodeMods /JsCodeShift.
I may be missing something obvious here, and I'm not a Python expert, but isn't this "get rid of all the emojis, except for one I like" code snippet completely wrong (despite the article's assertions that "it works fine," "the LLM used a neat hack," etc.)?
It seems to always just erase the file, because it declares `keep_emojis` to be a list of one element (`keep_emojis = ['¯\_(?)_/¯']`) and then goes USV-by-USV through the file to check if the encoded/decoded coded char is "in" keep_emojis. And there's basically no way that any single char can be. So the output is always empty.
If we wrote it like `keep_emojis = '¯\_(?)_/¯'` instead, then it would be a little closer, but in that case the program ends up preserving all non-ASCII characters (including all emojis), because these characters become the empty string after emoji.encode('ascii', 'ignore') and are therefore always "in" the keep_emojis string, so they never get replaced.
The explanation also doesn't make any sense, where it writes: "In the above code, the assumption is made that any ASCII character that cannot be encoded using UTF-8 is an emoji."
That's silly, because every ASCII character can be encoded in UTF-8. It also doesn't correspond to what the code is doing -- what it's really doing (I think) is testing for USVs that can't be encoded in ASCII, but then throwing the char away no matter what.
And, of course, the vast majority of non-ASCII coded characters in Unicode are not emoji, so this is not really a good way to satisfy the user's request. The roundtrip through ASCII seems like a bad idea -- if the user wants you to preserve some emojis while getting rid of most emojis, converting to ASCII (where there are no emojis) doesn't seem like it will be helpful.
Of course it's amazing that ChatGPT is already good enough to produce something close enough to fool venture capitalists into trusting it without trying the code, and these techniques will doubtless continue to improve.
This actually gets at the heart of the problem with the current batch of LLMs.
They have no concept of truth, and so will gladly generate tokens that are "likely", but are at best clearly wrong, or worse look correct to a non-expert, but are subtly wrong.
With software at least you can run it and inspect the behavior for flaws. Or have the results be validated by an actual programmer for correctness. And hopefully the developer using the LLM understands the limitations, and understands how it can hallucinate incorrect but convincing results.
However even software engineers I know, who are aware of all of the above issues, will ask ChatGPT questions about fields they aren't familiar with and view the results as authoritative. It's the same effect as when you read a news article about a topic you're familiar with and can immediately see flaws, shortcuts and exaggerations; but then you turn the page to a topic you aren't an expert it and say to yourself "what an interesting article".
The example from the article is even worse, since the author asked for an explanation of the code, and it hallucinated a clear and convincing but completely wrong explanation. Again to a programmer it is obvious, but to a layperson it's actively deceptive.
I could easily imagine a scenario where some asks ChatGPT, what is the best combination of chemicals to clean mold from a ceramic surface, and it responding with "Bleach and Vinegar are the perfect way to clean a ceramic surface." and following up with an explanation like "Vinegar de-greases the surface allowing the the disinfectant power of the bleach to penetrate into the mold". Which all sounds reasonable, unless you know beforehand that those chemicals mixed produces toxic chlorine gas.
Now that was definitely a contrived example, but unless you know and constantly question the output of an LLM you could easily be misled. Especially if you are asking about topics outside of it's training data or with minimal training examples.
Maybe with enough training data or some combination of transformers with reinforcement learning that has a "truth" metric, hallucinating completely incorrect information can be reduced to an acceptable level. But at this point it seems intractable.
You seem to be talking about giving the LLM the responsibility to do both strategy and tactics. In my experience, it can be useful in tactics, but usually fails to understand the concepts of strategy.
My personal feeling is that an LLM is insufficient for strategy and is not the only technology suitable for implementing the tactics. I think it makes more sense to treat each as a module in a system, and build different modules to compete against each other.
I know they aren't optimized for truth, that was the point of my comment. But based on my own experience of showing people ChatGPT, without explaining the flaws they tend to treat the output as if it was.
>> This actually gets at the heart of the problem with the current batch of LLMs.
Here you are implying that the fault lies [solely] with LLMs.
>> They have no concept of truth, and so will gladly generate tokens that are "likely", but are at best clearly wrong, or worse look correct to a non-expert, but are subtly wrong.
Hear you are asserting that you have the means yourself to reach truth. This is extremely easy to do if you're speaking abstractly, but try executing that at the concrete level (as above) and it's pretty difficult to avoid imperfection.
Regarding the difficulty of truth, is the problem here entirely with LLMs, or is the problem with reality itself?
When ChatGPT (or anyone/anything) says something "is" true (and some people agree) someone else says it "is" not, how are we to decide which is correct?
Where does this "is" that people "are [only] perceiving" come from? Where, and what, "is" "reality"?
Is the universe equal/identical to reality? That's how a lot of people talk...but is it true?
INB4 "we could all be brains in jars", which is one of the most common responses to arise "purely by coincidence" when this topic is raised.
I used it to help me wire up some solar panels in series / parallel, and while mostly helpful, it messed up on some math, which with electricity could have resulted in a fire. Luckily I am skeptical and noticed, but I just as easily could have not.
>ChatGPT is already good enough to produce something close enough to fool venture capitalists
VC funding is centered around making high risk/high payout bets in quantity. If they took the time it would take a functioning prudent investor to carry out due diligence, the startups would have already used up their runway and died.
VCs trade risk for reward, and make it up on volume. Fooling a VC isn't a high bar in the eyes of this Midwesterner.
This actually gets at the heart of the problem with the current batch of hype around LLMs.
The people writing this kind of blog either don't have the ability to understand, or didn't bother to check, that they just fired their software development team and replaced with with the software equivalent of a cargo cult. Just because the code highlights in the IDE does not mean the revenue will come.
The crazy thing is that this is super common in many posts about LLMs! Here's another example that was recently on HN:
What I think the author wanted was to remove ASCII emoticons, because there is no such thing as ASCII emoji. Another confusing thing is that good 'ole shruggie (which in this form I'd classify as an emoticon) is not pure ASCII, and relies on Unicode codepoint 0x30c4 for the smiley face, and a couple more besides.
The author did such a poor job of describing what they wanted, it's no surprise the generated program is nonsense. If anything, I'm now less convinced that non-technical people will be able to use conversational AI tools to usurp my hard-earned societal role as a technologist.
Humans are generally not very good at describing what they want. Transferring messy descriptions into the code asking questions in the process is what software developers do.
I stopped reading this after realizing that most of the article depends on an assumption that is unlikely to happens, which is that AI can produce high quality and complex software.
One important aspect of software is that it's not much easier to read than rewrite the code. Currently AI generated code needs much reading and checking, and some rounds of chats to iterate. I am even not quite happy to read humans' code, nevertheless AI's.
Only when one day AI can code that needs little human intervention will the article mean something to me. But is that ever possible? The crux is that a software bug is not in the code, it's the mismatch between the code and our mental model. Programming language is a precise way for us to present the mental model. Without a program, how do we tell AI precisely of our mental model? By natural language we can never do that. Even we can do that, we're only repeating a program in a extremely unconvinent way.
I do agree that AI can help developers spend less time on boilerplate and creeping in documentations. It can greatly improve productivity of the software industry.
AI is definitely coming from some jobs previously considered creative. See [1], on HN today. I expect it to come for many web-related jobs in the near future. Large language models by themselves are basically cut and paste programmers. But that's good enough for some routine work.
This is just getting started. Large language models coupled to more structured systems are going to be very powerful agents.
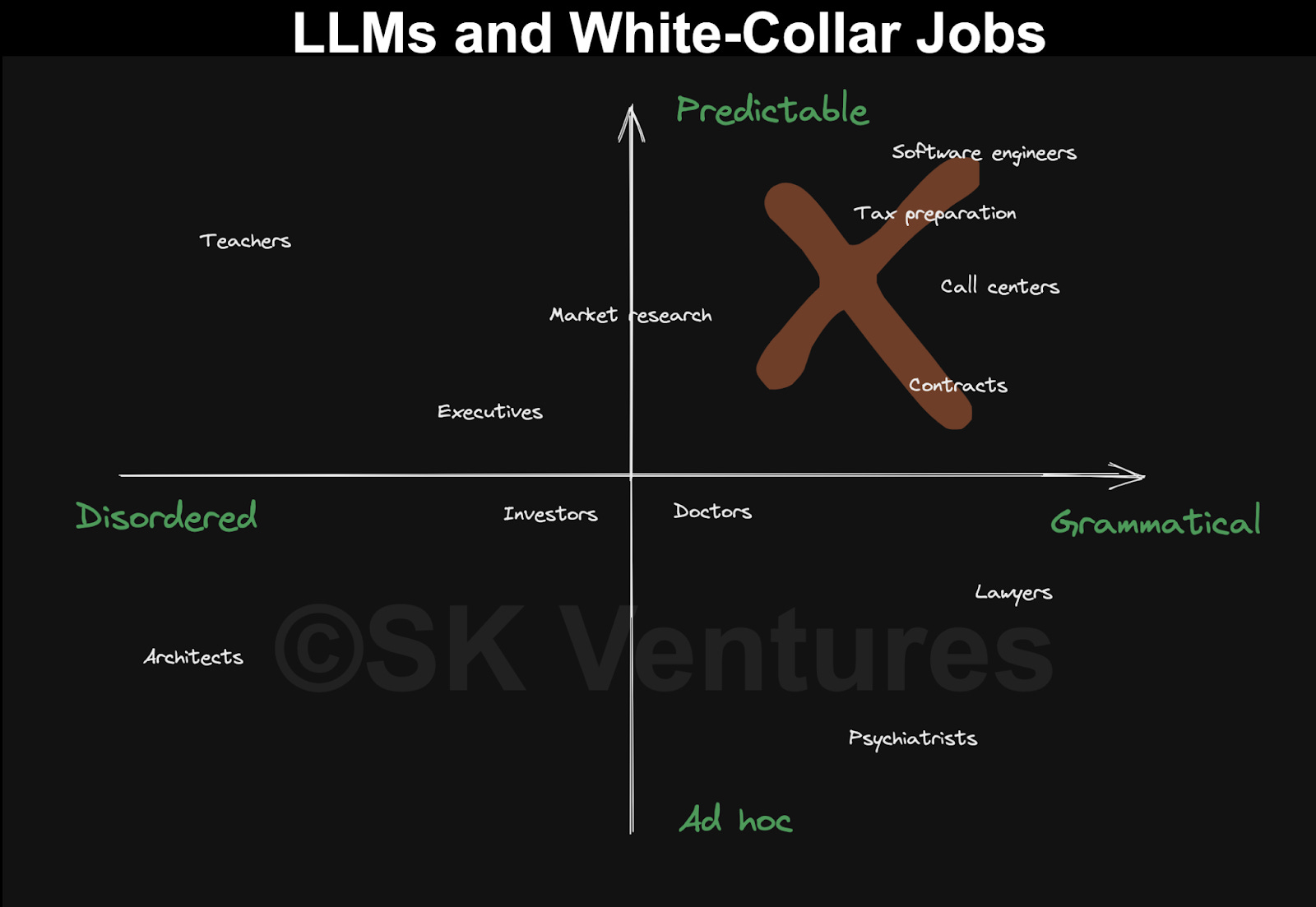
That graph places software engineers in the top-right quadrant, suggesting that they are predictable and "grammatical". However, I believe there should be a distinction between writing code and engineering. I would not classify software engineering as entirely predictable. For instance, while you could use a script to handle emojis with ChatGPT's help, it would be challenging to use the same strategy for a solution involving large systems that have multiple failure points and span multiple regions. Moreover, even if such a system were successful, multiple redundancies would need to be in place to prevent large-scale disruptions caused by downstream failures.
On the other hand, the chart places executives and investors on the 'safer' side. However, I think that with the real-time information available to AI, investing as a 'job' could be at a higher risk of being replaced. The same could be true for many executive positions (assuming that we are comparing merit-based positions to those based on nepotism).
Agreed. All these people that think their "soft" jobs are safe. Nope yours will be the first to go. The last to go will be the ones that require actual physical presence.
Also, it's looking more and more like jobs that involve hard math and logic will be sticking around for a long time in the new AI regime. I have tried to get chatgpt, copilot, and llama to write lock-free stacks and other examples of simple but difficult code, and it has not gone well.
"Soft skill" jobs like executives and managers are definitely on the chopping block first.
It's already happening - HR departments and recruiters are getting the ax in most of the major rounds of layoffs. An AI system that can write "nice" emails will replace at least half of HR jobs these days.
I think the "ladder climbers" aren't going to be fully replaced, but their ranks are already getting thinned, too.
I do think a future where AI can generate convincing-but-subtly-flawed blog posts like this one is closer than one where chatgpt generates correct, on-spec production code. Maybe influences and hustlers will be the first to go.
Someone should make an AI-generated crypto-influencer persona. Virtual YouTube, Twitter presence. Mint a new coin once per week, hawk it to the masses. I bet they could make decent money.
I am afraid that as long as humans are writing code there will be other humans in charge of ensuring their work is profitable. We won't be able to do away with executives just yet, unfortunately.
What ASCII emojis? This guy doesn't have the first clue. The generated code is garbage. The explanation is nonsense. "Gutenberg Moment", where you are found out as the gargantuan fraud you are?
This is like a tick above the fucking whitepapers that crypto frauds used to have to sell their coin.
I hope this isn't too informal for HN, but... commenting here to mark this momentous instant, where the software engineers were warned and dismissed it as hype.
However, let's take a step back and consider a few basic arguments that this article makes - I suspect most here would only disagree with the very last.
Firstly, the demand for quality software is far greater than the current supply. If there were suddenly twice the number of mid-level software engineers, there would still be more than enough work for them.
Secondly, software engineering is a process that can be refined and created almost entirely without the interference of non-deterministic real-world systems like roads, weather, or courts. This makes it an ideal field for automation and AI to play a larger role.
Thirdly, a sufficiently intelligent computer could exponentially increase its own efficacy in performing purely-digital tasks -- basically an [intelligence explosion](https://www.lesswrong.com/tag/intelligence-explosion) but much softer and much much more achievable (how smart is a mid-level SWE, really?).
Finally, LLMs that get a ~100 on an IQ test are enough to start that cycle.
Perhaps you're super duper convinced that the last point is wrong. Perhaps you have strongly-held convictions about explainability, symbolic reasoning, higher level thinking, etc. But if you really sit down and think, what are the chances you're wrong? What are the chances that we get another leap or two in the next 1-5 years like we just got with DL transformers?
If you're feeling excited and anxious about the implications of this, you're not alone. I've found that it's a difficult topic to discuss with those close to me, especially if they're not familiar with the latest developments in AI. If you have thoughts on how to use our SWE experience to navigate this exciting but uncertain landscape while maintaining a sense of self-preservation and helping others as much as possible, I'd be interested in hearing your ideas.
> If you have thoughts on how to use our SWE experience to navigate this exciting but uncertain landscape while maintaining a sense of self-preservation and helping others as much as possible, I'd be interested in hearing your ideas.
The last point is neither right nor wrong, it's fanfiction.
The second point is wrong. You can automatically synthesize code from a specification (and you could already do so before LLMs, arguably even better with SMT solvers), but who is going to write the specification in the first place, buddy?
That's the problem that's never been solved, and it will never be solved because it can't be solved. It is not easier to write a specification in English than it is to write it in C++. It's like saying that math would become easier if we took away the burden of using mathematical notation. Not only it wouldn't get any easier, it would get significantly more difficult!
Lies are dangerous, because if you say too many of them, you start believing your own. "AI is like a human you can talk to", they said. Now they act as though that's true, and they talk to the AI, without realizing it's the same faithful mechanical slave it has always been, perfectly capable of carrying out nonsensical instructions to their nonsensical results.
And the instructions are necessarily nonsensical, because they insist on using an interface too wide, where saying something precise is all but impossible.
Writing a spec is a problem that can be broken down into sub-problems and so on. It’s not magic, and while the LLMs of today may do it poorly, there’s nothing special about the task that would prevent better models from doing a decent job. I’m sure if someone posted on here 5 years ago that they were building an AI that could at an image and tell you what’s funny about it, people on here would be foaming at the mouth to explain how impossible that task is, that only humans possess the subjective viewpoint and je-ne-sai-quois of human… and now here we are.
> Writing a spec is a problem that can be broken down into sub-problems and so on.
Yes, a.k.a. programming.
If you assume that you have a machine powerful enough to do that, then you have a machine powerful enough to do anything at all: you are assuming the thing you're trying to prove.
There exists no universe where a machine that can do whatever you want by being instructed verbally isn't also replacing the one instructing it...
I share much of your sentiment and find it surprising how difficult it’s been to discuss the matter and find developers willing to have a serious discussion about it. There are serious market forces at play here that will impact all of us. I don’t have time right now to write an adequate response, but will do so soon and appreciate reading a post like yours.
I definitely think a lot of people here are missing the forest for the trees. A lot of the arguments seem to boil down to “it cannot do this now, so people won’t be able to make it do so later”, which seems naive. Look at what Microsoft is investing in this tech - is anyone actually thinking that they won’t be able to figure out how to add structure to the output, or better train the models, integrate it better with stakeholder requirements, or whatever else? HN loves being contrarian, but in this case I think it’s more curmudgeon than contrarian.
The problem with this line of thinking is that it's essentially doom-scrolling. It's especially bad because ChatGPT came along during an industry down-cycle. An interesting thought experiment is: if hiring was like 2021, would your take be different?
In terms of AI taking ALL THE JOBS... Maybe it will happen? Maybe it won't. But what action can we take from all this doom-scrolling? Other than "we should all be VERY CONCERNED." Which is just a way for us to stand around wringing our hands.
My conclusion is much the same as always: I can't grow complacent. Which we've known for years. "The industry is changing." Of course it is. It's been changing for ~80 years. And if you go back to similar advances, you'll see similar arguments.
Will this time be different? Maybe. But until it does, I think I'll continue to learn new skills (not just new languages/frameworks), refine my problem solving and troubleshooting, and above all, refine my people skills.
But I think I'll avoid the doom-scrolling. Either AI is coming for ALL THE JOBS or it isn't, but even knowing that it is doesn't give me anything actionable to do about it.
It’s definitely sort of scary to me, but I’m hoping that it’ll be like previous times we have automated stuff - we’ll develop more advanced jobs on top of the new tech. So I don’t mean to be doom and gloom!
Also posting here as a bookmark for the future. I'm pretty sure most SWE's are toast, I've been pair programming with gpt-4 for the last weeks and it is freakishly good compared to gpt-3. It's just a matter of continuing on current trajectory of progress and most SWE's will be completely obsolete within 5 years.
Conflating technical debt with financial terms is an interesting tact, but I feel it is a bad tool for analysis. Their own chart shows a declining cost of software. I feel that complexity (not the lack of refactoring away technical debt) is a far better proxy for analysis.
The complexity inherent in software development reached a minimum in the era of Visual Basic and Borland's Delphi, and has rapidly increased since then in the abandoning of the Windows Desktop and the Win32 UI as a standard and fairly reliable platform for applications.
It was possible to build and deploy applications in a rapid enough fashion that agile just happened without prompting in many one-man development projects. In fact, many domain experts were able to craft their own reliable and usable (to them) applications that remain in use to this day. That world existed, and has largely been abandoned.
I suspect what AI tooling will enable in aggregate (if we're lucky) is a return to the levels of productivity we previously had, despite the multiple new layers of interfaces and abstractions inherent in the non-Win32-GUI world we now inhabit.
Thus, I feel if you want to see how AI/LLMs are going to effect the economy and our profession, look to the effects of the Win32 desktop on software in terms of size and scale of disruption. History doesn't repeat, but it does rhyme.
-- EDIT/APPEND --
in an era of "free" debt, where the interest is effectively zero, management learns to spend money like crazy, and let the debt stack up, because it is the efficient thing to do
When that management mindset is mis-applied to understanding when the programmers say "we've got tech debt we've got to pay off".... they incorrectly assume it has no cost in interest, and can be ignored, as with money debt...
except it does have interest.... loan shark levels of interest
All these people commenting on the positive relationship between amount of code and technical debt. Generative AI can refactor code too (making it smaller)
Another piece where a plausible looking but completely nonsensical code generation output is uncritically presented as correct. At least it is a quick way to see either the author has no idea about software development or doesn’t care about facts in their arguments.
You know the old saying "familiarity breeds contempt"? I believe the opposite is true as well. People who don't code think coding is typing. People who don't manage think it is as simple as forwarding emails from executives to subordinates.
I myself have often wondered if what doctors do couldn't be automated. You have the primary care physicians who seem to run on a loop of "listen to symptoms" - "order tests" - "prescribe medication" - "refer to specialist". And the specialists themselves seem to follow their own loops. Many surgeons for example, perform the exact same procedure day in/day out for decades. Surely well-trained robots, not prone to fatigue or loss of dexterity as they age, could produce superior outcomes.
But they haven't been replaced yet, just like I haven't, so I assume there is more going on there than what looks from the outside like repetitive manual labor.
> Again, programming is a good example of a predictable domain, one created to produce the same outputs given the same inputs. If it doesn’t do that, that’s 99.9999% likely to be on you, not the language. Other domains are much less predictable, like equity investing, or psychiatry, or maybe, meteorology.
> Entrepreneur and publisher Tim O’Reilly has a nice phrase that is applicable at this point. He argues investors and entrepreneurs should “create more value than you capture.” The technology industry started out that way, but in recent years it has too often gone for the quick win, usually by running gambits from the financial services playbook.
{kind=link}
reply