The amount of activity and progress in the LLM/ML/AI spaces is truly fantastic. Optimizations like this are particularly valuable when hardware (e.g. Nvidia) is so expensive.
Is it that a lot of capacity is unused in those behemoth LLMs, or that the smaller language model just mimics the reasoning task? (Mimics the mimicking?)
There is no actual distinction between the "real" thing and "mimicking".
The datasets behemoth LLMs are trained on include a lot of noise that derail progress. They also just contain a lot of irrelevant knowledge that the LLM has to learn or memorize so an obscene amount of parameters is required.
When you're not trying to teach a language model the sum total of human knowledge and you provide a high quality curated dataset, the scale barrier is much lower.
That’s what the fine tuning is about. It learns the language, concepts etc. from the main dataset and is then tweaked by continuing to train on a smaller, high quality, hand curated dataset. That’s how it learns to generate conversational responses by default instead of needing a complicated prompt.
My go-to analogy for this is: an LLM trained solely on true facts will still say untrue things for the same reason that an image AI trained solely on photos of existing people will still generate images of people who don't exist. Training the AI more narrowly restricts the scope of what it can generate, but in general I don't think it reduces hallucination (especially since you're training on less overall data).
It has to learn the meaning of words, including implicit associations, and to do that it needs to see approximately all the English text ever. We don't know how to balance this with only feeding it useful knowledge.
It doesn't necessarily have to see approximately all the English text ever. Real people don't learn English like that, for example.
It's just that given what we know about neural networks, it's often easier and simpler and more effective to increase the amount of training data than to change anything else.
Unfortunately models aren't always good at knowing what they don't know ("out of distribution data") so it could lead to confidently wrong answers if you leave something out.
And if you want it to be superhuman then you're by definition not capable of knowing what's important, I guess.
Yes, LLMs and human brains share at most some faint similarities.
Nevertheless, human feats can act as an existence proof of what is possible. Including of what might be possible for a neural network.
(I'm not sure whether a large language model necessarily needs to be a neural network in the sense of a bunch of linear transformations interleaved with some simple non-linear activation functions. But for the sake of strengthening your argument, let's assume that we are assuming this restrictive definition of LLM.)
> Or did the authors count the amount of training data for the LLMs to the required training data for the destined/task-specific models?
Yes.
They are counting the amount of data you need to collect to solve your problem. I can grab a pretrained LLM, and the data I have to collect in that instance is what I need to fine tune it.
Apple's hardware advantage is something I'm hoping to see really unleashed with the M3 generation. The fact the A17 Pro has ray tracing support is giving me hope they can catch up with the incumbents quickly. It's honestly the one thing that has kept me away from their newer hardware-- I primarily use my computer at a desk and PC hardware (GPU primarily) is leagues ahead of what their very best can do. I honestly can't justify spending nearly 4k when Linux works great for everything I do professionally AND when I'm done with work I can still play a game.
I disagree. ML is eating the world by storm and one thing Apple loves is high margins. Folks like myself would gladly pay that margin to someone besides Nvidia. I paid $2k for my last GPU and was happy to do it. That doesn’t even factor the fact that businesses would pay even more when the alternative are machines that start in the tens of thousands for just the GPU ability. GPUs right now are carrying fat margins and that makes more than enough incentive for Apple IMHO.
You can find many leaked email threads from Apple where they talk about the value of high powered local compute. It is a fundamental part of their strategy. They do not want the cloud approach for high end compute like Google, they want you to have high end and powerful devices in your hands.
That number is not quantized either. Quantize 175B param at 4 bits then it'd fit in ~120GB VRAM (one can fit 34B models at 4 bit quantization in a single RTX3090 24GB VRAM)
> Would be amusing if they were to release a Mac Pro with 300+ GB and dominate the LLM serving space
Is there any framework that can batch LLMs on Metal? I don't think GGML or MLC have it yet.
Otherwise that is just another reason they wouldn't be good for LLM hosting at this moment.
Anyway, the real disruptor is Intel. They could theoretically barge in with a 2x48GB Arc card and undercut the market that AMD/Nvidia refuse to dive into because of their Pro card clients.
Its really a shame that Apple (and AMD/Intel or pretty much any other infrence vendor) are not directly contributing to llama.cpp. The feature set is amazing and growing at a stunning pace.
I imagine the legal concerns around it are part of the reason. Where I am, our legal team has been very direct, that anything llama based cannot touch a work computer.
Curious to know why this is the case? I haven't played around with LLAMA yet but I figured it being open-source would make it more trustworthy than models provided by OpenAI.
Absolutely not. The LLAMA license [1] is clear that it's not open source. It's for non-commercial, research only, and only by explicit permission from Meta. The weights were leaked, on 4chan [2], illegally, according to the license. Very very few people are using it legally. This interpretation is clear from its wording, and also matches the interpretation of our flock of lawyers.
I am wondering who will be the first to raise RAM capacity of their hardware offerings dramatically to win the LLM crowd. Seems like the way to win market share.
Agreed. I would love to have something with the FLOPs of a 3070/4060 and 80 gigs of even slower VRAM (not necessarily HBM/GDDR6x) that can run the XXB models.
There's AI-research supremacy and there's AI-product supremacy. Google has many brains (pun intended) on the former, but lacks incentive/structure for the latter.
They're often also slow to market. They weren't the first search engine, they weren't the first email platform, they weren't the first video site, but now they're the biggest in those categories. I think Bard's growth will be very interesting to watch given that track record.
It’s not getting dropped. If OpenAI’s models get good enough, search traffic will crater and Google will fall on extremely hard times for lack of ad revenue. At the same time, if they fail to integrate state of the art generative features into Workspace, people will go to Microsoft, where GPT-4 is presently handing Google their ass. Yes, Google Duet for Workspace totally sucks; I suspect their trial conversion rate approaches 0%.
This is a make it or break it problem for Google and they will get it right or they won’t get it at all.
I have for programming searches. ChatGPT can give me things that would take 5+ minutes of searching to hone in on. Then again, I run an ad blocker so no loss for them.
Honestly google probably doesnt make any money at all on searches like "how do call rust from python?". They make money on searches with buy intent where people search for "buy gps for car"
For any domain specific questions or discussions I use ChatGPT because it’s so much better than Google. People underestimate how many fields it’s already valuable in beyond programming.
I use Google for basic bitch things like finding a company website or what time is it in Tokyo.
I have a browser extension (ChatGPTBox) that puts ChatGPT one click away on every DDG search I do, and it's certainly now often where I go next if DDG doesn't get me the result vs appending "!g" (to send the search to Google).
In that respect it's not replacing all my searches, but it seems to be replacing the "hard ones" where it's hard to compete with Google at a disproportional rate. If that is actually the case, it'd spell bad news for Google whether or not it kills search - if it becomes cheaper/easier to compete by offering a mix of less complete search with an OpenAI integration, it opens the door for far more attempts at competing with them.
not at all. I feel (this data is from running SEM for large website(s)) that Google earns most of their revenue from tactical searches. For instance, most people search for website names instead of typing the url. This creates a massive tactical search traffic base for google and brings largest revenue for them. There is a huge competition in this category as most competitors bid on others.
Similarly, product searches are second largest category in which they make tonnes of money. This is also done by people as they don't really like to search on amazon or other ecommerce sites. This is also a huge money spinner for them.
Both of these are not going anywhere as both of these are tactical spends.
Now let us come to long tail. These are again big money and are at risk for Google. However, you have to understand that Goog ads are clicked by most tier 2 users. We, techies, do not really click at ads. We go for organic ranking (mostly). We are the base of chatGPT right now. Tier 2 and lower users don't really use chatgpt.
Even if they do, they would not do it for product discovery or site discovery as it has too much friction: go to chat.openai.com, type in your question, it responds in slow, jerky manner vs just type in browser bar what you are thinking.
To top it, Chatgpt also has stale data. Moreover, it is heavily lobotomized to not give any controversial or edgy answers. This curtails usefulness of chatgpt.
I think new generation using tiktok for search had more impact than AI.
The current issue with chatGPT is the freshness of the data, accuracy second to that. If they manage to constantly feed their model with new data then it might be a true contender imo
It's worth mentioning that the Google you're talking about was way way different than it is today. Google Search was a startup. Google Search + Email was a small company. Google Search + Email + YouTube was a midsize firm. Now they're a humungous megacorp that's slow to make necessary changes when there's a paradigm shift like LLMs.
I agree with the point you are trying to make, but Google Search + Email was not a small company. I remember Gmail Beta, Google was already known world over and definitely not a 'small' company.
Android didn't win, they just prevented Apple to have a 100% monopoly on smartphones.
Edit: Apple is certainly taking the lion's share of profits in the phone space. Since Google isn't investing as heavily anymore in Android, the development has slowed considerably.
Define winning - I'd take "Android maintained its position as the leading mobile operating system worldwide in the second quarter of 2023 with a market share of 70.8 percent. Android's closest rival, Apple's iOS, had a market share of 28.4 percent during the same period." [0]
Arguably Google is the company that triggered that paradigm shift by publicly sharing (some of) their work on AI like the transformer/attention paper. So if anything they were ahead of the curve in terms of research. They're also extremely well positioned in terms of training data, infrastructure capabilities, hardware (TPUs), they had the first popular machine learning library (TensorFlow), etc.
Lately you could argue they're being overtaken by their competitors, especially in terms of productization. But they still hold pretty cards IMO.
They were the best search engine from the get-go and had a massive impact. Gmail/maps also to a lesser extent.
In AI they were giants in what looks post-ChatGPT like a mediocre field. Their search now is looking very jaded.
The trajectory here isn't remotely like their past performances; it's not a safe bet to assume they'll win through with Bard or anything else.
The agility of OpenAI and the revolutionary impact of gpt3+ has made the former incumbents like Google look like posturing, self-satisfied, giant lumbering has-beens. They aren't getting back on top without massive internal changes.
Bard is getting decent in search results. They adopted some patterns Phind took in early interfaces with citations and made it much better in terms of interaction and response time compared to what Phind is doing today.
Also, with more recent changes I can get decent summaries much easier (and at no cost to me) for every document in a google drive.
In my day to day, those features can be pretty powerful tool, even if its not at GPT4 level 6 months after GPT4 and Bard were released in March.
To my knowledge, no one is really integrating search at the level that Google is with generative language models.
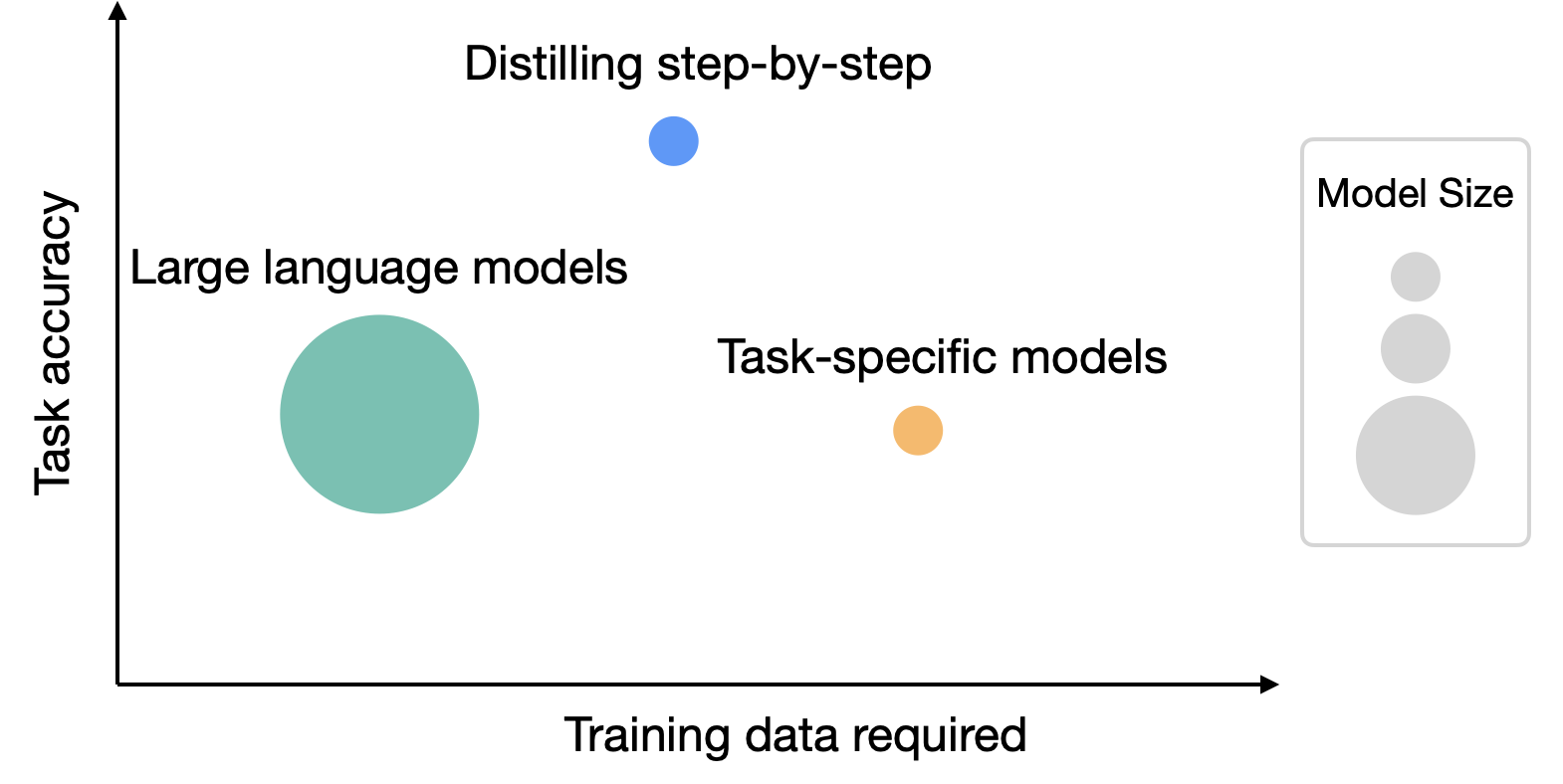
The article is just a fine-tuning concept that could have been published by anyone, using any large LLM and small LLM in combination. This has nothing to do with marketing.
The title refers to them outperforming their previous SotA model with one a tenth the size by building off one of last year's most important research papers in generating additional synthetic data which effectively exports domain knowledge from the larger model to the smaller.
All this AI angst going on right now is ridiculous.
Yeah, every technology gets a hype cycle these days.
But not every technology has research cycles this fast.
In fact, I can't think of anything that's had research cycles this fast.
Interesting that they use T5 for the distilled model. I was under the impression that encoder-decoder architectures were on the way of the Dodo, but it seems they may still be relevant after all.
Also interesting is that this isn't an inconceivably clever and out of the box idea. It shows there's still a lot of low hanging fruit to explore, and the future of LLMs isn't set in stone yet. Could be that the real deal is a mixture of experts trained in this style. It's exciting that it feels the holy grail is close to being achievable if only the right combination of ideas is tried.
It's definitely a very similar method but fundamentally different in that the 'Distilling step-by-step' approach is a multi-task model.
As I understand it, rather that training the smaller model to produce the CoT/rationale as a part of the (decoded) response, it actually has two output layers. One output is for the label and the other is for the rationale. The other layers are shared, which is how/why the model is able to have an improved "understanding" of which nuances matter in the labeling task.
They actually have a performance edge, but they aren't well suited to chat models because you can't do caching of past states like with decoder-only models
T5 family is awesome. FastChat-T5 has amazing text generation quality (eg for RAG chatbots) and it can easily run on CPU fast enough to do a live conversation.
The paper mentioned was submitted in May. I think encoder-decoder architectures still make a lot of sense for multimodal models.
There are still many low hanging fruits. I have probably seen dozens of variations of chain-of-thoughts, tree-of-thoughts, graph-of-thoughts, self-ask, self-critique, self-plan, self-reflect, etc.
Is there a paper, or some other source, that synthesizes this grab-bag of techniques? As an interested outsider, it's hard to keep up with all the action. Would appreciate any pointers that try to bring some of the pieces together.
There are too many papers. Even experts won't read all of them.
This survey is pretty good. Covers most important topics about LLMs.
Challenges and Applications of Large Language Models
https://arxiv.org/pdf/2307.10169.pdf
I don't know what exactly your interest is.
There are various good podcasts, blogposts, newsletters.
If you want to find paper lists for a particular area, you can look for survey papers, reading list of topic courses(stanford ones are usually pretty good), google "awesome xxx" e.g. "awesome graph learning" (this also works for tech).
You can also search something like "best deep learning paper 2022", "top 10 xxx 2022", "must read xxx 2022". (sometimes you get clickbaits)
You can also look for the latest paper in that area, then check the citations on google scholar. (you need to filter on your own)
Thank you for that. I wonder if you'd be able to just post a link to the paper, or give its title? I didn't have a Meetup account, tried to create one, spent 4 minutes dicking with it, and still can't get it to let me in.
> given the input question “Sammy wanted to go to where the people are. Where might he go? Answer Choices: (a) populated areas, (b) race track, (c) desert, (d) apartment, (e) roadblock”, distilling step-by-step provides the correct answer to the question, “(a) populated areas”
Huh? My answer as a human would have been "race track", as that is probably "where the people are" (during a race).
Did I fail? Am I a poor language model? Or is the whole thing just tea leaf reading to begin with?
Yeah "I felt lonely and wanted to be where the people are, so I wandered through the suburbs" really doesn't make sense. I think this is just a bad question.
"Where the people are" doesn't simply mean "where a large number of people live". It also has connotations of "where it's happening", as in "where people are coming together (right now)".
But my point is really that speaking of the correct answer with a question as vague and open to interpretation as this one is absurd.
Indeed, I pattern matched (a) as the correct answer too, but on reflection on the content of the words and what it would all actually mean, I think that (a) is a bad answer. If we aren't careful we'll train our AIs to be good at giving incorrect, pat answers to inadequately thought out questions.
Training an LLM on a ton of multiple choice questions doesn't "infect it" like you're thinking. The tokens capture the fact it's a multiple choice question, and the LLM eventually captures the nuance of textual entailment as a common form of multiple choice question.
In a more natural conversational setting, you'd get a different answer:
> Did I fail? Am I a poor language model? Or is the whole thing just tea leaf reading to begin with?
No offense to you, but I never would have picked "race track". That answer doesn't make much sense since the original prompt doesn't mention anything about racing, and the definition of a populated area fits well with the question being asked.
Fascinating. I would 100% pick race track. Maybe because populated areas is plural? Or because the question gives a named subject and nobody would ever respond to "where are you going?" with "populated areas"?
But if I watch F1 on TV there are a lot of people there. A race track is like a stadium, it’s a place constructed for a spectator sport. It may be empty most of the time but when there is a race on then there will be crowds there.
“Populated areas” does not mean much. Montana is a populated area. It’s not a highly populated area but it’s populated alright.
I am not a researcher, but it always seemed intuitive to me that the most effective models would be multimodal and trained with a core carefully tailored curriculum.
I would want to ensure that the system gains and retains the fundamental structures and skills that you know it needs to effectively and accurately generalize. While maintaining those things you then feed it lots of diverse data to learn the exceptions and ways the skills can be combined. But somehow you need to ensure those core skills and knowledge throughout. Maybe you could do that just by including outputting those understandings or manipulations in addition to the final answer. Similar to what the paper does.
For example, a code generation model might be required to output a state machine simulation of the requested program.
I agree that multimodal seems like the way to go, but it's not at all intuitive why we should expect the curriculum needing to be carefully tailored. Compare https://gwern.net/scaling-hypothesis
Yeah so far looking at the progression since 70s, domain-specific attempts stagnant while just-increase-the-input-and-core attempts get us where we are now
My impression is that while domain specific models do better in their domain. They do not generalize well and cannot be transferred to different domains without retraining. Hence comes mixture of experts (domain specifics). The trick is to juggle them all. Which needs another quite capable 'manager' model. The good thing is that they can be trained separately. Also at inference there in no need to call them all. Existing models, like GPT-4, can be used to create datasets for experts, or enhance/balance existing datasets.
I can very well believe that empirical this can work. (I haven't checked the literature.) My point was merely that given my priors, this isn't intuitive.
Pondering on the idea of school curriculum. I wonder whether the order the training data is fed will make a difference. Whether it’s fed starting from simple things to more complex or vice versa. The gradient descent surely can end up in a different, better or worse, local minimum?
I think smaller expert models will dominate the majority of applications. there is an optimum and fine balance to strike when it comes to size and usability. There will be many mechanisms like demonstrated in the post to find that optimum and realize it.
It's not a likely solution given how loss functions work, but in theory a single model could learn to perform exactly the function you describe. When you say "just do X" where X is any function (in this case, a piecewise function), a large enough model could do it.
After some reflection, it's maybe more accurate to visualize this in reverse: all expert models see the problem and attempt a solution, and then some "manager" model decides which expert model has the best solution and outputs it.
Any memoryless continuous function between two Euclidean spaces, I think you mean. The experts-and-manager model would need to be able to do more than that (as do most neural networks).
And part of the reason why single-hidden-layer networks aren't enough even in continuous memoryless Euclidean cases is, again, because of how loss functions work; you're unlikely to converge on a good approximation with very few hidden layers.
I agree but I am tired of the argument that "all you need is two layers" I hear from (obsolete) academicians all the time so I pointed out the practice is completely different even if theory says so.
It would get more complex with cross domain questions. Part of what makes LLMs feel magical is their ability to synthesize such disparate topics and information into coherent “thoughts.”
I would suspect what you have instead is a single model attached to data sources, where the model doesn’t have to have so much compressed fact, and instead can rely on higher level summary.
This approach would remove one of the main benefits - the ability to run multi-task one-shot prompts where a single LLM call returns answers to multiple NLP tasks.
TLDR, the essay explores how LLM could evolve into front-end routers that connect users with specialized tools, leading to a future where federated models determine the best-suited system to answer specific queries. Not too different from today's federated search approaches.
I did a senior reading/research class in AI back in 1989, as my final class I needed to graduate with a BSCS. The idea originally was to do a survey of the methods known at the time and determine which was the best. This included things like e-mycin, the first generalized expert system toolkit.
I ended up with the premise that each of them had their relative strengths and weaknesses, and it would actually be best to use all of them, but only in their own areas of strength. Then have them use something akin to a shared blackboard where they could all read the results from the other systems and write their results as well. That the sum of all the available algorithms working together, each in the areas in which they were best, would result in better outcomes than any one algorithm could achieve on its own.
My professor was not impressed. I only got a C.
Now, the story of how my dad had to work his ass off to finally get the College of Engineering to force the professor to actually give me a grade that he owed me, when all the professor really wanted to do was focus on his new job at one of the big airlines -- well, that's a story for another time.
Interesting! Do you think RLHF would be a necessity for smaller models to perform as par as state-of-the-art LLMs? In my view, instruction tuning will resolve any isssues related to output structure, tonality or the domain understanding but will it be enough to improve the reasoning capabilities of the smaller model?
{kind=link}
reply